This thread is for any discussion of the WACZ Format, designed as a portable, standard way to exchange web archive collections, and allow efficient loading of large collections in the browser.
1 Like
Thanks @ilya for creating this thread. I am looking for a way to extract the content of wacz files into my local file system so we can analyze what we recorded and see every single media file (pictures, png etc…). Is there a tool to see all documents as we would see them in the network tab of the dev tools ? Do you have any advises about how to examine wacz content ?
Maybe this is too low level, but one thing you might want to consider trying is to first unzip your WACZ file, since it’s a zip file:
unzip -d archive archive.wacz
This should give you a directory structure like:
example
├── archive
│ └── data.warc.gz
├── datapackage-digest.json
├── datapackage.json
├── indexes
│ └── index.cdx
└── pages
└── pages.jsonl
You can use the index.cdx file to look for URLs that might be of interest (PNG, JPG, etc) and then use that information with warcio to extract it. For example for a CDX entry like:
com,cdninstagram,static)/rsrc.php/v3/ya/r/fm_vua6unuv.png 20221016184419008 {"url":"https://static.cdninstagram.com/rsrc.php/v3/ya/r/FM_vuA6unUv.png","digest":"sha-256:cc24b28534e05155bcd77124355bedda63d6e548e516bfd2e3d7be37b485f543","mime":"image/png","offset":25260548,"length":6582,"recordDigest":"sha256:76f118aa4bc7180b1b18332ccb07b6feb15fc15eec2e9bdad081d86f1ac2cd0d","status":200,"filename":"data.warc.gz"}
You could extract the image file:
warcio extract --payload archive/data.warc.gz 25260548 > file.png
But depending on what you are doing that could get a bit tedious. You could extract all the resources using warcat to the file system and look at those instead.
python -m warcat extract archive/data.warc.gz --output-dir data
That will extract each file and write it to the filesystem using the original URL as a filesystem path.
I’ve been experimenting with a small client-side JavaScript tool that lets you examine one or more WARC files. It’s quite limited, but in theory could be extended to present a listing of image resources, that type of thing.
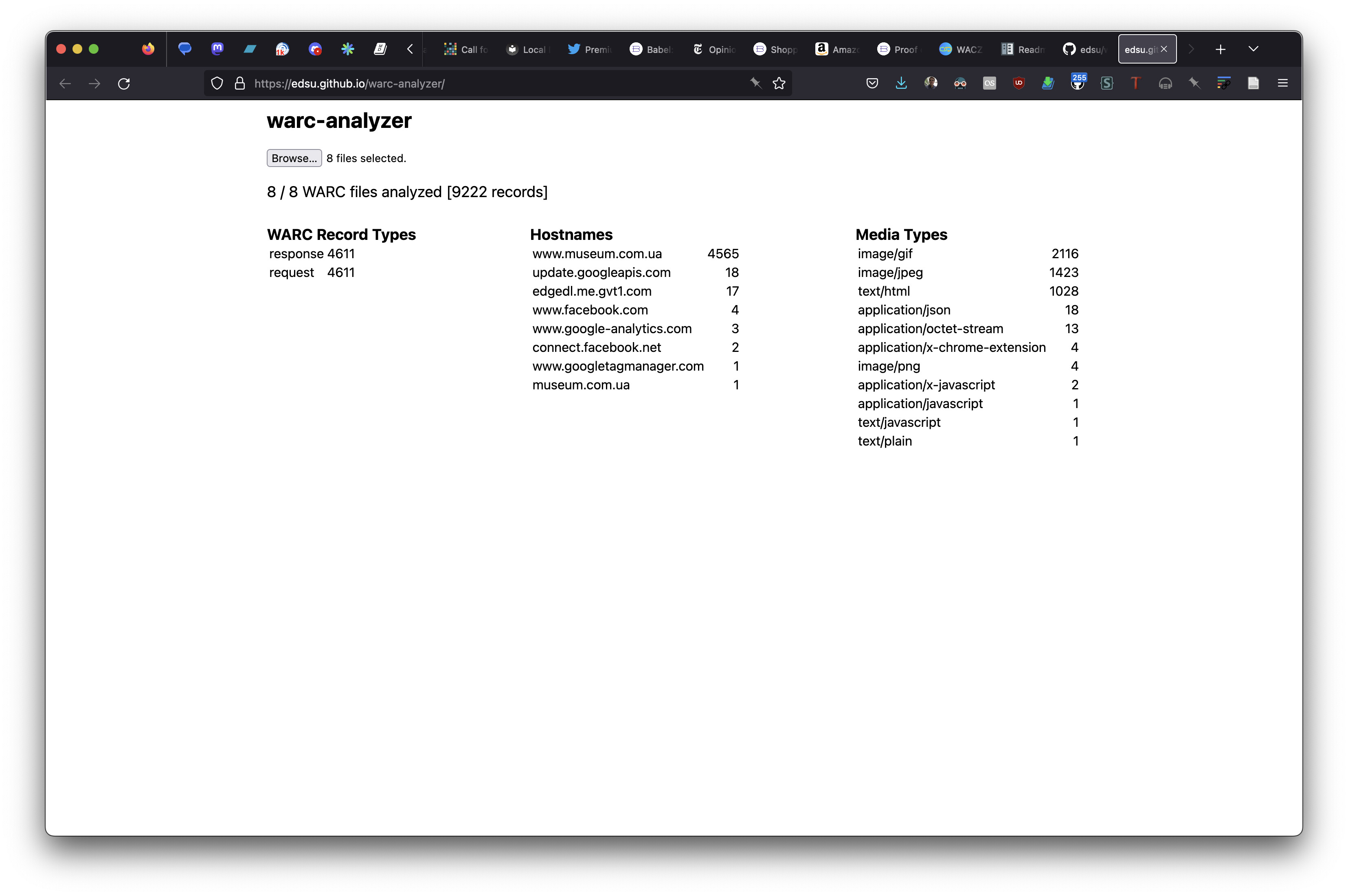
I’m curious to see where this thread goes–I was glad to see you post about this @philc since it comes up quite frequently, and I’m not sure there’s always satisfying answers. It would be interesting to hear more about why you need to do this–what’s the particular use case?
1 Like
Thanks @edsu for your helpful reply. I did unzip the wacz and gunzip the cdx index but then to really open the data within it I used warcat extract and it created for me a directory hierarchy similar to the urls of my page content. The problem is that the the video file is being breakout as many files with this type of file name ./instagram.ftlv5-1.fna.fbcdn.net/v/t50.2886-16/298732277_600341848195334_5250677162004745198_n.mp4__nc_ht=instagram.ftlv5-1.fna.fbcdn.net&_nc_cat=102&_nc_ohc=7sjnHGobYucAX9TDccO&edm=ALQROFkBAAAA&ccb=7-5&oh=0_922a6b and I cannot really access the video content.
Most I want is to examine the media contents of the archives to make sure we captured it. I would be glad also to have a view of the remaining content elements such as html, css, js but media are the most important. Any more ideas ?
1 Like
Nice, I’m glad you were able to get that far. As you discovered, most video delivery platforms don’t make a discrete video file available, since it is streamed. The series of requests that make up that stream all get their own unique record in the WARC file. If you are trying to make sure you captured it I would recommend loading the WACZ in ReplayWebPage and navigate to the page where the video is, and ensure that it plays? Manually checking for successful replay is unfortunately the state of the art in Quality Assurance in web archives at the moment.
Intersting indeed. I wonder which video player can take those chunks of mp4 and play them in a similar way my browser succeed to play them.
When I tried to open those chunks as produced by warcat using vlc I got most of the files reported as 00:00s length and one with 14s length but no one can play and I am getting this error on the console:
I wonder how to open those video chunks to validate the wacz content
[000000010b506a00] main decoder error: buffer deadlock prevented
2022-12-14 12:01:01.377 VLC[68238:3682432] Can't find app with identifier com.apple.iTunes
2022-12-14 12:01:01.421 VLC[68238:3682432] Can't find app with identifier com.spotify.client
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x110810200] trun track id unknown, no tfhd was found
[mov,mp4,m4a,3gp,3g2,mj2 @ 0x110810200] error reading header
[000000010b506010] avcodec demux error: Could not open /Users/philc/tmp/archives/09_00_44_output/instagram.ftlv5-1.fna.fbcdn.net/v/t50.2886-16/298400106_3152281124989276_2322128332072778657_n.mp4__nc_ht=instagram.ftlv5-1.fna.fbcdn.net&_nc_cat=104&_nc_ohc=jXhU0w2m9fEAX-wlHBx&edm=ALQROFkBAAAA&ccb=7-5&oh=_55552a: Unknown error
[0000000130723f80] mp4 demux error: MP4 plugin discarded (no moov,foov,moof box)
If you want to dive into the details you may want to look at how tools like youtube-dl and similar tools work. I think this may be a bit out of scope for Webrecorder tools which are focused on preserving and replaying the HTTP traffic. But if you find anything useful you want to share here please do!