We would sometimes need to crawl non-page content.
A simple seedlist of urls, where we want to download and archive all the content.
It could be seedlists of urls to images, javascripts, pdf, rss, etc.
Would this be possible in browsertrix? When trying this with an url to an image, I get this error:
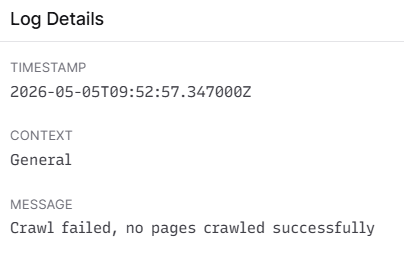
If it is not possible now - maybe in the future?
All the best
Thomas