I’m looking for a way to cancel a running crawl in browsertrix-cloud. The API seems to have a crawl cancel endpoint, and I get a success response when cancelling the running job directly using curl, but nothing seems to change. Also deleting the pods and PVCs manually did not help here, as everything is recreated (which is good!).
a) Is the cancel endpoint supposed to be functioning? (looking in the code, it looks like it is)
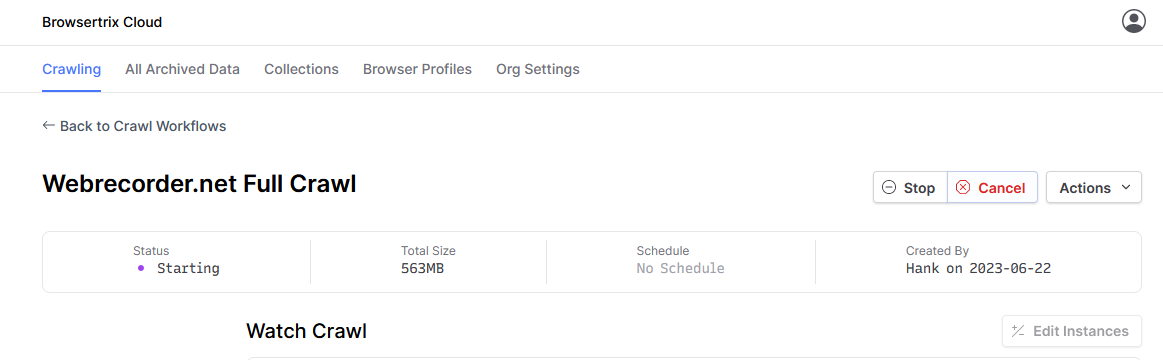
b) Is there a way to cancel a running crawl from the frontend?
Yes, you can cancel a running crawl via the actions menu of the crawl workflow, or the details page.
It’s also worth noting that stopping a crawl is different from cancelling one. Stopping will retain all the data crawled up until it ends, whereas cancelling will throw it away.
Thank you for showing this clearly! Somehow I had missed the UI location for this.
That the crawl didn’t actually stop after calling the API endpoint (we had insufficient resources for starting a new job, hence the job was running for a week without anything happening; after fixing the k8s nodes and waiting some days, the job is completed now), it must have been a rare case I triggered. Good to know it is normally working.
It was indeed odd that the job didn’t cancel right away – as we’ve tried to make cancelation pretty robust, but I guess more work is needed there. The operator is supposed to delete all of the pods when it receives a deletion (finalization) request – it only waits for the PVCs to be destroyed as well.
I suppose if the operator was somehow not running, due to resource constraints, perhaps it never got the request… We’ll try to reproduce this on our end.
We may need to use pod priority to keep track of this better as well.
Let us know if this happens again.
Thanks for adding your thoughts here, that’s helpful! The operator was running, because when I deleted pods & pvcs manually, they were recreated. I’ll keep an eye open when this happens again.
Could you say how you fixed it? I have a similar problem: I start a job via the web interface, but it never starts due to insufficient resources. Not sure how to troubleshoot it.
If your problem is that a job never starts due to insufficient resources, you may need to scale up your cluster / troubleshoot why no new pods are being created. There can be many reasons, that is something to debug on the Kubernetes-level.
If you can’t delete a job from the UI, I think that could be a bug. If you’re comfortable trying things manually - and probably brake something, so don’t just try this - you can probably interact with the crawljobs resource kubectl get crawljobs (probably in the crawlers namespace), and delete it there if the problem is that the Kubernetes-part is not deleted (but this will probably break things in in browsertrix-cloud!)