I am using the ArchiveWeb.page chrome extension.
I want to capture webpages after it is modified by my userscripts.
For example, this userscript uses the GitHub API to add some info to the repo page:
https://i.imgur.com/Xv6gW5d.png
Originally, I didn’t think this was possible to capture. I thought the extension simply records network traffic, and cannot see DOM modifications made by userscripts, therefore cannot capture the modified page.
However, surprisingly, I was able to search the archive for the text added by the userscript (/![]() 2020-02-10/
2020-02-10/![]() 584/
584/![]() 41/
41/![]() 44.69MB):
44.69MB):
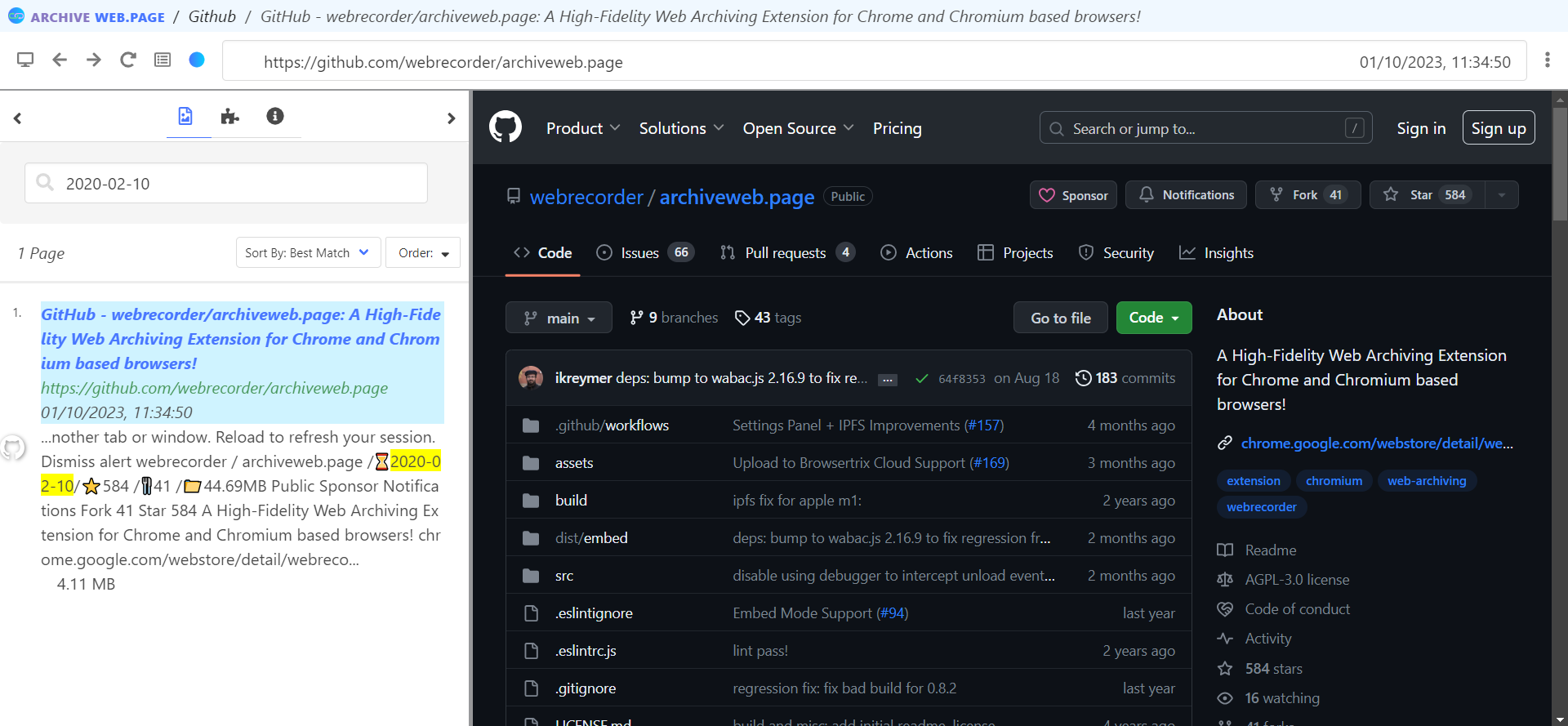
It seems that the extension indexed the text content after the userscript ran? However this text is missing from the actual archived page.
How can I modify the extension to capture the page after userscripts run, so that “/![]() 2020-02-10/
2020-02-10/![]() 584/
584/![]() 41/
41/![]() 44.69MB” will be visible on the archived page?
44.69MB” will be visible on the archived page?
Also, some userscripts adds interactive elements on the page (e.g. clicking on “![]() 41” will open the fork list), is it possible to capture these as well?
41” will open the fork list), is it possible to capture these as well?
Note: The GitHub userscript is just an example, I don’t actually archive GitHub repos like this.
As another example, I have a userscript that replaces thumbnails with high-quality original images by modifying the “src” attribute. When the browser loads the original images, the extension records the network traffic and stores these images into the archive. However, the archived page will still use the thumbnail src, and will not display the original image.
I believe that there is some value in capturing these “non-original / altered” pages, because these userscripts add additional information to the page that would otherwise be lost.