Hello! I’ve been playing with Browsertrix Cloud. I work in a public university system that gives away websites to students, organizations, individual faculty members, and projects. I’m looking for solutions to archive those projects.
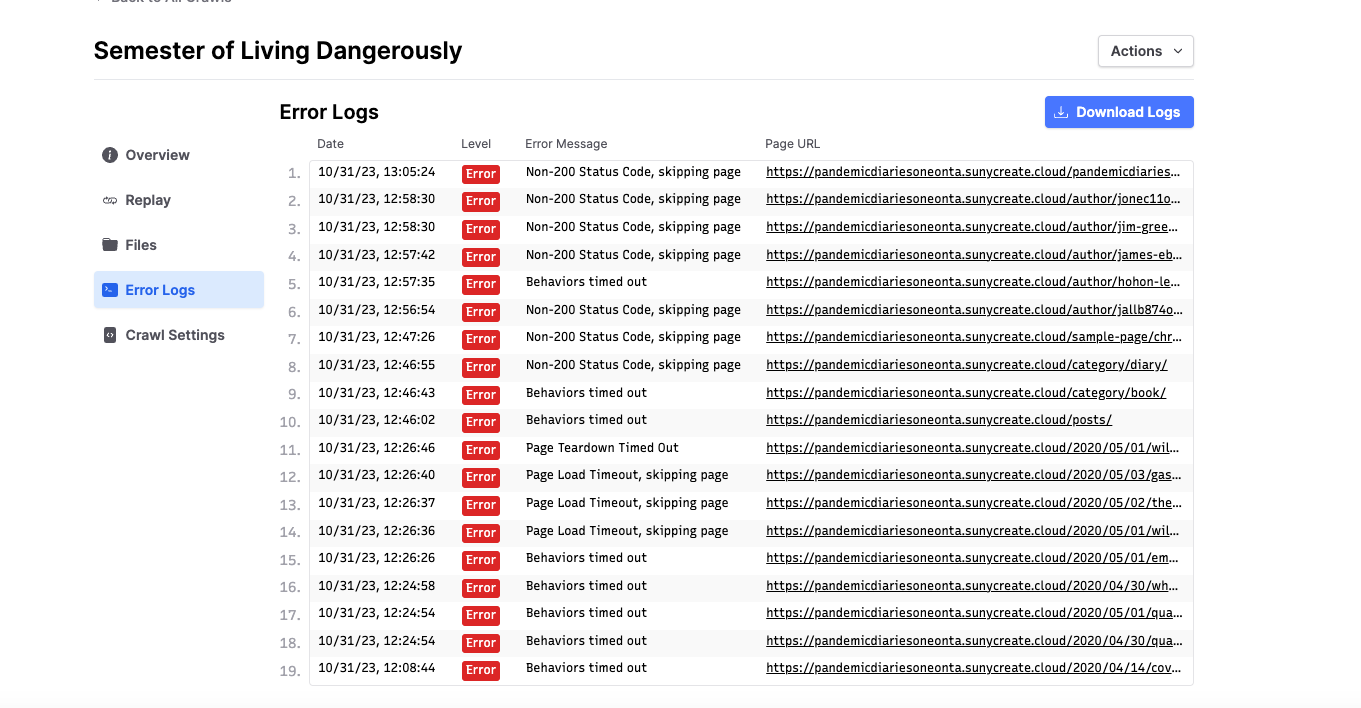
When I ran the crawler on BrowserTrix Cloud- I got 19 errors caught by the machine, plus another error that shows up on nearly every page that might be a tougher nut to crack.
I got 19 errors or pages that were not included in the Web Archive. The troubling thing is that none of these pages were actually problems. Meaning that if I look at the pages now, they are online and I don’t see any issues.
What I did was download my archive file and load it into ArchiveWeb.page, and then revisited those pages manually, adding them into the archive. But I thought there must be a simpler way to do this that I am missing. Is there a way to ask Browsertwix cloud to retry on pages that it timed out on? If that doesn’t currently exist, would that be a good feature request?
The other issue I am seeing is a WordPress / Jetpack feature that shows related posts at the bottom of a post.
At the bottom of the posts page, they show links to three similar posts. While that is visible in my archive, when you click on the links, it shows the JSON of the WordPress Block instead of being treated as a link.
For archiving the site, I might just disable that feature and retry, but I thought since WordPress is such a popular website creation tool I might ask if anyone has a work around.
I got 19 errors or pages that were not included in the Web Archive. The troubling thing is that none of these pages were actually problems. Meaning that if I look at the pages now, they are online and I don’t see any issues.
Not all of the crawl errors are showstoppers, these are meant to show you what happened for various pages so that you can maybe refine your settings for the next run. For example, since behaviors timed out for a number of pages, you could set the behaviour timeout higher in your workflow for the next run of the crawl. Similar for page load timeouts.
Unfortunately we don’t have a way for the crawler to auto-retry with a higher timeout at this point. Some pages such as those with infinite scroll will always time out, since there is never ending content if the browser continues scrolling.
What I did was download my archive file and load it into ArchiveWeb.page, and then revisited those pages manually, adding them into the archive. But I thought there must be a simpler way to do this that I am missing. Is there a way to ask Browsertwix cloud to retry on pages that it timed out on? If that doesn’t currently exist, would that be a good feature request?
This is a version of the easiest way to handle manually patching crawls at present. The sort of “canonical” way to do this at present is to make a new archive in ArchiveWeb.page, capture just the pages you want that weren’t perfect in the crawl, then upload that to Browsertrix Cloud and combine your crawl and uploaded patched content together into a Collection, which can be replayed and downloaded together as a single WACZ.
The other issue I am seeing is a WordPress / Jetpack feature that shows related posts at the bottom of a post.
We’ll also be working on assisted QA soon, and part of the longer term hopes for that is that if there are errors we can automatically handle without manual intervention (such as retrying again with higher timeouts, perhaps), that could happen as part of the QA process. Stay tuned!
 Meaning that if I look at the pages now, they are online and I don’t see any issues.
Meaning that if I look at the pages now, they are online and I don’t see any issues.