Hi Peter,
Yes, we actually just deployed an update to 1.17.5, which should fix the ‘^’ appearing. Also just tested it on your account for an existing workflow that you had.
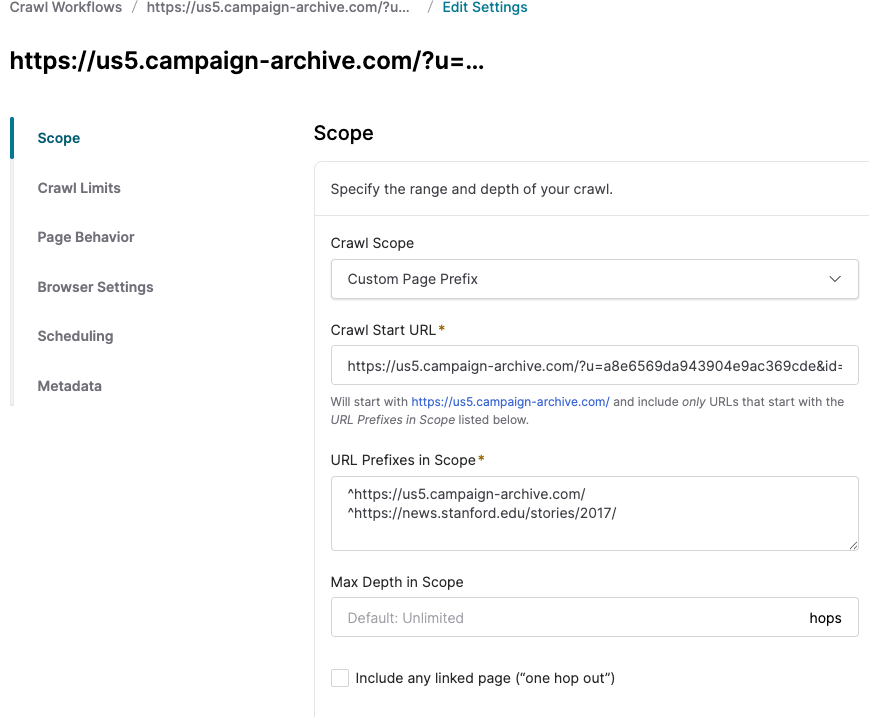
Also, it may be that the scope should be https://news.stanford.edu/2017/ and not https://news.stanford.edu/stories/2017/ looking at some of the links.
Please try again on the latest version and hopefully it works as expected now!
Hm, perhaps there is an easier way to do this - you’re trying to crawl 1221 pages and all links from them that are to https://news.stanford.edu/, or with a different scope per page?
We will be adding support for large seed lists in the next release, hopefully next week.