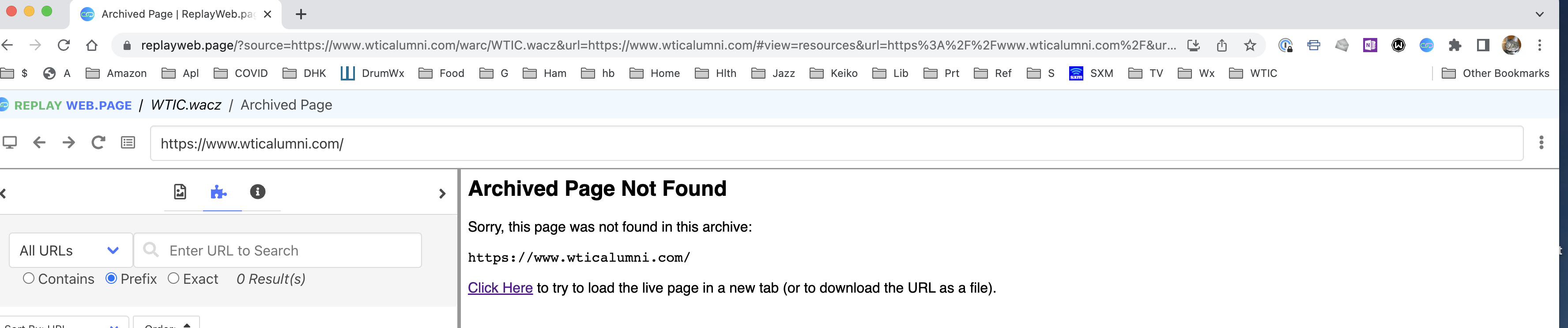
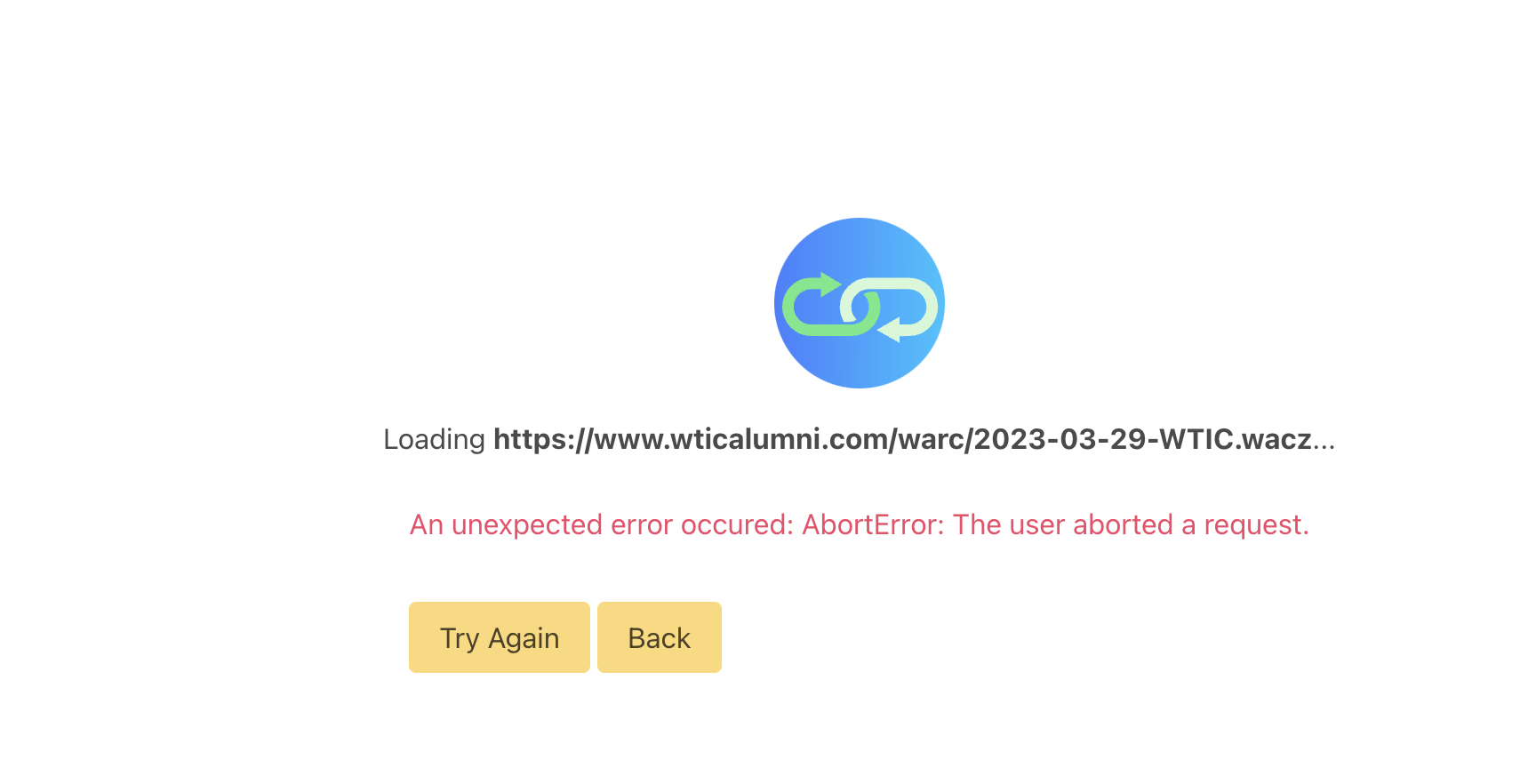
No one? In addition I’m finding that a newly created wacz won’t load either on any machine with the error: “An unexpected error occurred: Abort Error: The user aborted a request”
To get to the bottom of any issue you’re having here we’d need the actual WACZ file. The WACZs aren’t actually uploaded anywhere and the URLs you have sent here don’t actually link to them on the web. In order to load the file on your other computer you’ll need to move the file over onto its storage and locate it in replayweb.page again.
IDK how I missed that… Maybe I shouldn’t be responding to forum posts at 2 AM lol >_<
Trying your first link again seems to result in a CORS error (An unexpected error occured: TypeError: NetworkError when attempting to fetch resource.) on Firefox but works fine in Edge (Chromium). Pretty sure this is known behavior and we don’t have a workaround for it at the moment.
The link in your second post results in this error in Edge: An unexpected error occured: AbortError: The user aborted a request. which is strange becuase as you mention, visiting the link embedded in the URL works fine…
https://www.wticalumni.com/warc/23-04-04-WTIC.wacz results in a 404, I can’t access it.
I’ll have a look at the WTIC.wacz file locally and see if I can figure anything out?
Downloaded, tried loading it, says that 0 pages are found and doesn’t seem to load properly…
Which makes sense because datapackage.json & datapackage-digest.json appear to be missing in 23-04-04-WTIC.wacz? Unsure how you created this file but that would be a place to start.
I doubt Python is the problem here. For detaills on the following command line flags checkout the readme for py-wacz.
You should be able to validate your wacz files with wacz validate -f path/to/file.wacz. If that doesn’t work something is wrong with the file. In the case of your file 2023-04-04-WTIC.wacz ZipFile for Python reports that it’s not a zip file which is curious… WTIC.wacz validated fine.
I’d recommend creating the file with the --detect-pages and -t flags. Not including these flags means ReplayWeb.Page may be unable to find the index of pages it’s looking for within WACZ files. AFAIK, when you load WARC files it parses the file and generates this index which is why they take longer to load.
I tried re-creating the WACZ out of 2022-12-09 GoldenAge.warc and WTICAlumni.warc. The file was indexed however each page I tried to click got the “Archived Page Not Found” error. When I tried omitting 2022-12-09 GoldenAge.warc the resulting wacz file had the same issue. GoldenAge.warc notably loads without issue into ReplayWeb.Page.
I’m sorry I can’t find the root cause of the issue? Possibly unrelated, but in the future I’d also recommend making smaller WARC files, ~8GB is probably ideal to not run into browser storage issues when loading them.
for example. Could the wget be having problems creating WTICAlumni.warc? I really don’t know how I can use smaller files, as I’m trying to download the entire websites for archival purposes. I CAN do them separately, but that doesn’t help me with WTICAlumni, the bigger one.
I noticed that the wget command will create GoldenAge.warc.gz not GoldenAge.warc which your previous wacz command would pick up. Did you decompress the WARC file prior to packaging with wacz? I’m trying to replicate the problem myself by following your steps.
@edsu Thanks, I’ve just been deleting the gz, leaving the file as GoldenAge.warc or WTICAlumni.warc and then the command wacz create -o WTIC.wacz *.warc. It’s always worked fine until this month.
I did notice some warnings when generating the WACZ. They seemed to go away when removing the -t.
$ wacz create -f *.warc.gz -o testfile.wacz -t --detect-pages
Reading and Indexing All WARCs
Skipping, Text Extraction Failed For: https://www.goldenage-wtic.org/gaor-51.html
'utf-8' codec can't decode byte 0x92 in position 3258: invalid start byte
Warning: SAX input contains nested A elements -- You have probably hit a bug in your HTML parser (e.g., NekoHTML bug #2909310). Please clean the HTML externally and feed it to BoilerPy3 again. Trying to recover somehow...
Num Pages Detected: 151
Writing archives...
Generating page index...
Generating datapackage.json
Generating datapackage-digest.json
I put the WACZ on Amazon S3 and here it is in ReplayWebpage:
Although I should note though that my WACZ is 8.6GB. It sounds like your wget process is generating more than one warc.gz file? I’m not sure I’m understanding what you are doing here.