I’m trying to view/open WARC files I’ve downloaded from Webrecorder both warc1.0 and warc1.1 in a text editor to access the ‘warcinfo’ and ‘request’ information to confirm the WARC seed’s URL. I have not been able to open a comprehendible display for either WARC and WACZ files in Sublime, playing with different encodings (see two screenshots), Brackets (Mac), Notepad++, and Kedit (Windows)
The use case for this: My institution primarily uses Archive-It for web archive discovery, I’ve been test uploading warc 1.0 files from webrecorder to index to an existing seed in Archive-It. To make sure the uploaded warc indexes to the correct seed, I’ve been told to open the warc files in a text editor to confirm the url matches the url (seed) in Archive-it.
Screenshots opening files in Sublime
Any suggestions on how to confirm the URL within a WARC file?
I’m working on Mac, when I right click on the downloaded WARC or WACZ files I don’t have an option to decompress. Is there a third party tool I should decompress the files in?
If the WARC file doesn’t have a warc.gz extension then it is likely not compressed?
WACZ files are actually ZIP files, if you change the extension to .zip your operating system will probably recognize that you can unzip it by double clicking on it. Otherwise on the command line you can unzip to a directory my-archive by opening a Terminal and running:
unzip -d my-archive /path/to/my/archive.wacz
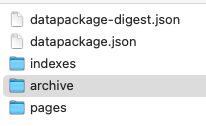
From there you should be able to inspect the compressed WACZ files in the my-archive/archive/ folder.
Thanks so much for providing this key piece of information! Once I changed the the WACZ file extension to .zip my operating system as able to unzip the file. The same logic worked for WARC files that were downloaded from ArchiveWeb.page: changed files extension to .gz
If anyone else reading this is curious what the unzipped WACZ structure looks like: ├── archive │ └── data.warc.gz ├── datapackage-digest.json ├── datapackage.json ├── indexes │ └── index.cdx └── pages └── pages.jsonl
Top folder screenshot:
Within the archive folder you can find a data.warc.gz file to unzip = a WARC 1.1 file type.