Hi all,
I’m attempting to use the py-wacz command line utility to create a single WACZ file from around 70 WARC files which were originally created with webrecorder technology around 2020. The goal is for this WACZ to be hosted in ReplayWeb.page for access and use.
I’m running into a few issues, first in the form of a few py-wacz utility errors, and then in ReplayWeb.page playback. I wanted to present them both here in case they are connected.
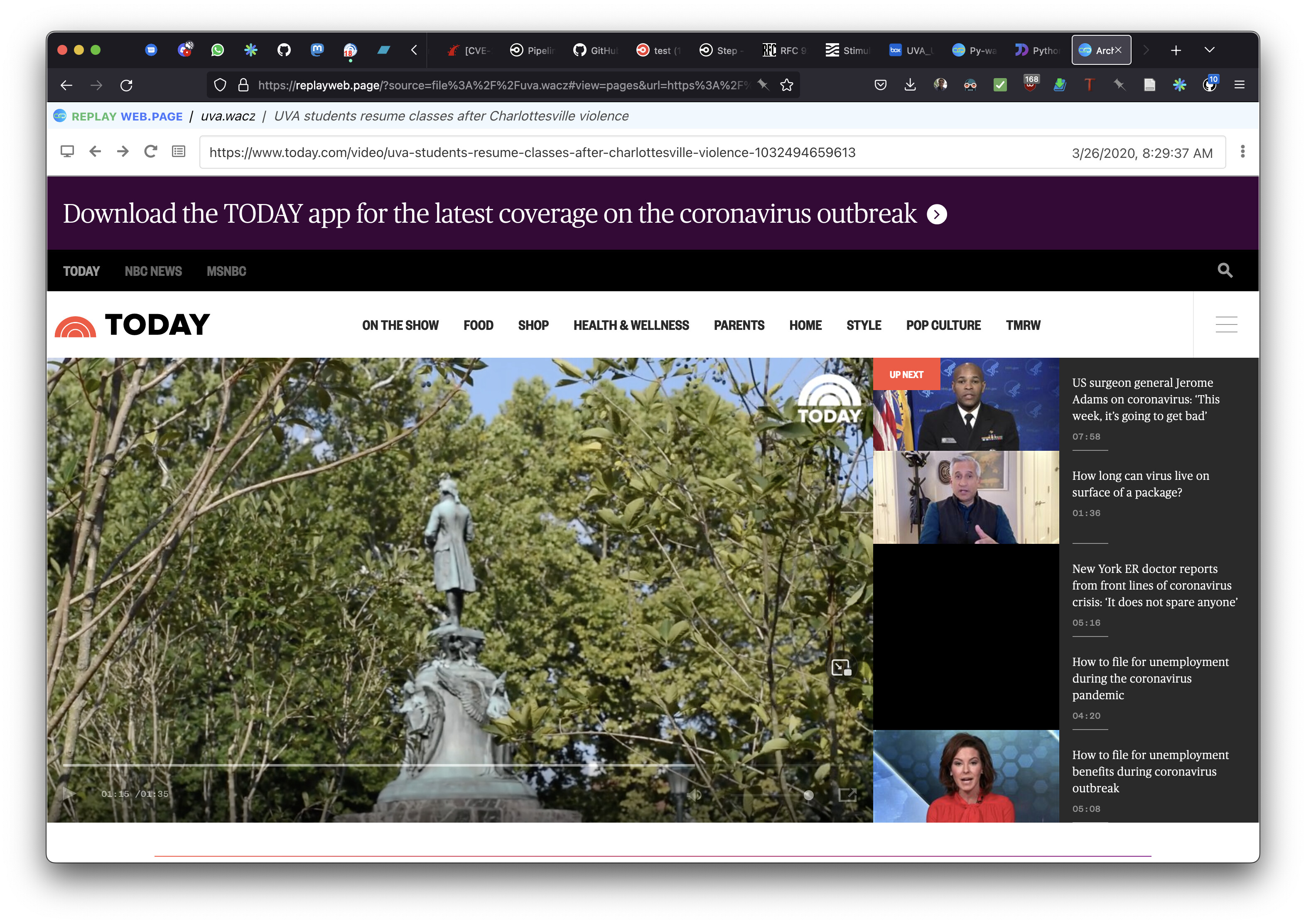
I tested a handful of WARCs to start (4 or 5) with py-wacz to ReplayWeb.page (just loading them locally from my machine). The py-wacz simple commands worked without error, and a wacz was created that I loaded into ReplayWeb.page. I did notice a message when viewing these materials before they would load that looked like this: 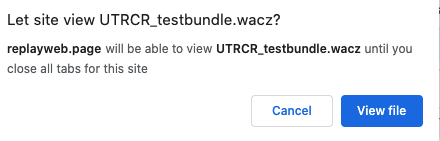
However, when I tried to start scaling up and loading 50-70 WARCS, I started to run into issues in py-wacz, which I thought might have stemmed from the warcs themselves. The errors that were thrown typically followed this pattern (I’ve used ellipses where huge blocks of text followed, except for the Error:\n):
Error parsing: {“action_group_id”:“8f1e0c32-5f55-d853-d9f2-bd7a60f15fff”,“version”:“3.11.11-generic”,“xkey”:“cvYGNal5xGaRZYDiS2z80aL3JULuLgSOakuDmdmt”…
Error:\n
Error: Unexpected coder setup failure:\nfunction(){var…
Even with these errors, py-wacz still created an over 2GB wacz file from my 70 or so WARCs, so I tried to load it into ReplayWeb.page. There, I ran into other issues that may or may not have stemmed from the py-wacz errors. Even though most pages showed as properly indexed, clicking on them to view showed a message that the page was not part of the archive (screenshot below):

This was the case for every page I tried to navigate to within the archive. I also tried to search and load specific URLs within the WACZ, but was met with the same result.
Thanks very much for any insight you can provide.