I tried to crawl https://cdnc.ucr.edu/, which includes the page Alameda Encinal 16 September 1869 — California Digital Newspaper Collection. This page is publicly accessible and does not require a login, as you can verify by visiting the link directly. However, I encountered a “reCAPTCHA validation error” when replaying this page in Browsertrix Cloud v1.16.2-e995811. The content was also not captured.
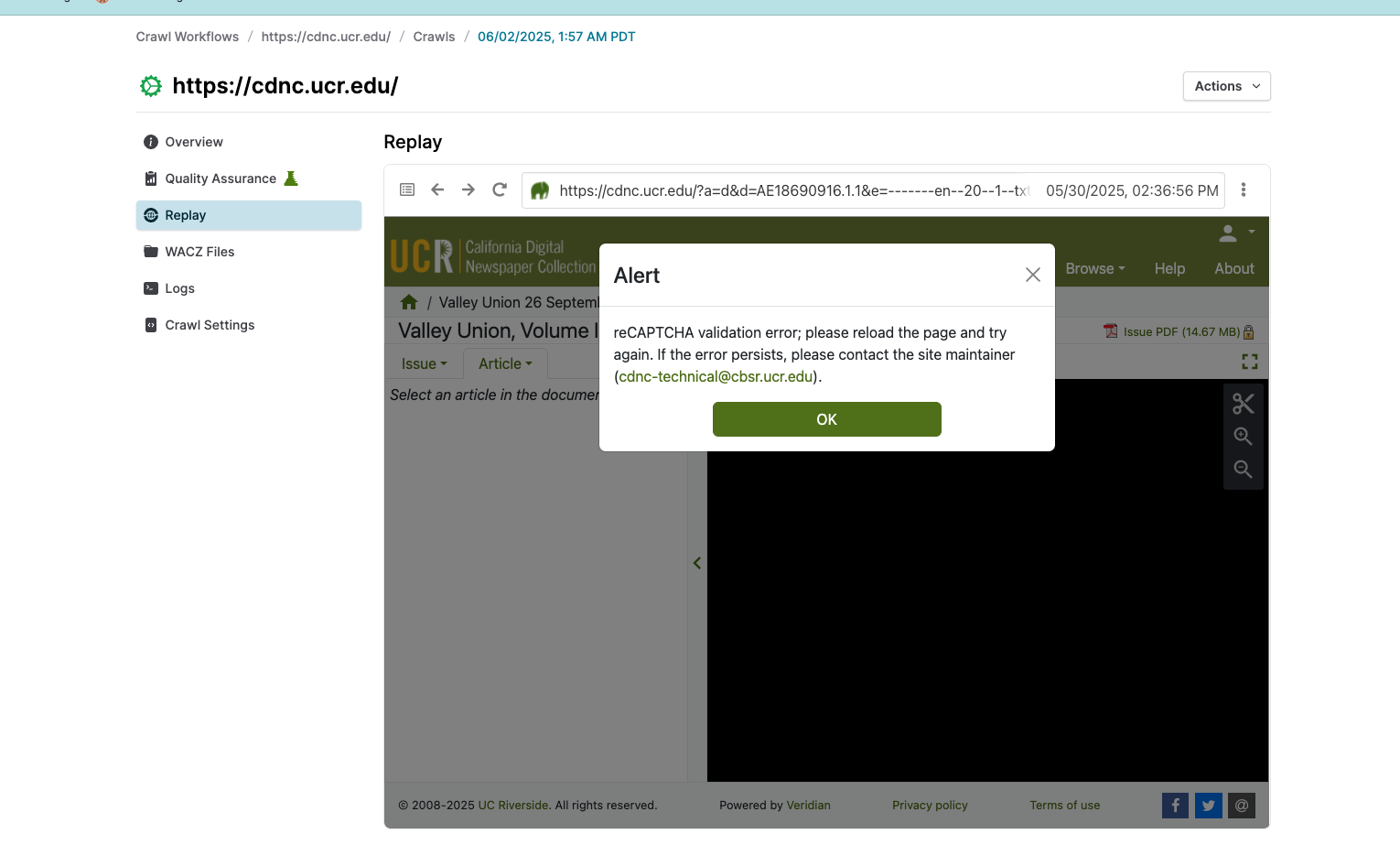
Any suggestions on how to fix that?