I’ve captured an Instagram Account with browsertrix-crawler using a browser profile.
The WACZ is 1 GB in size.
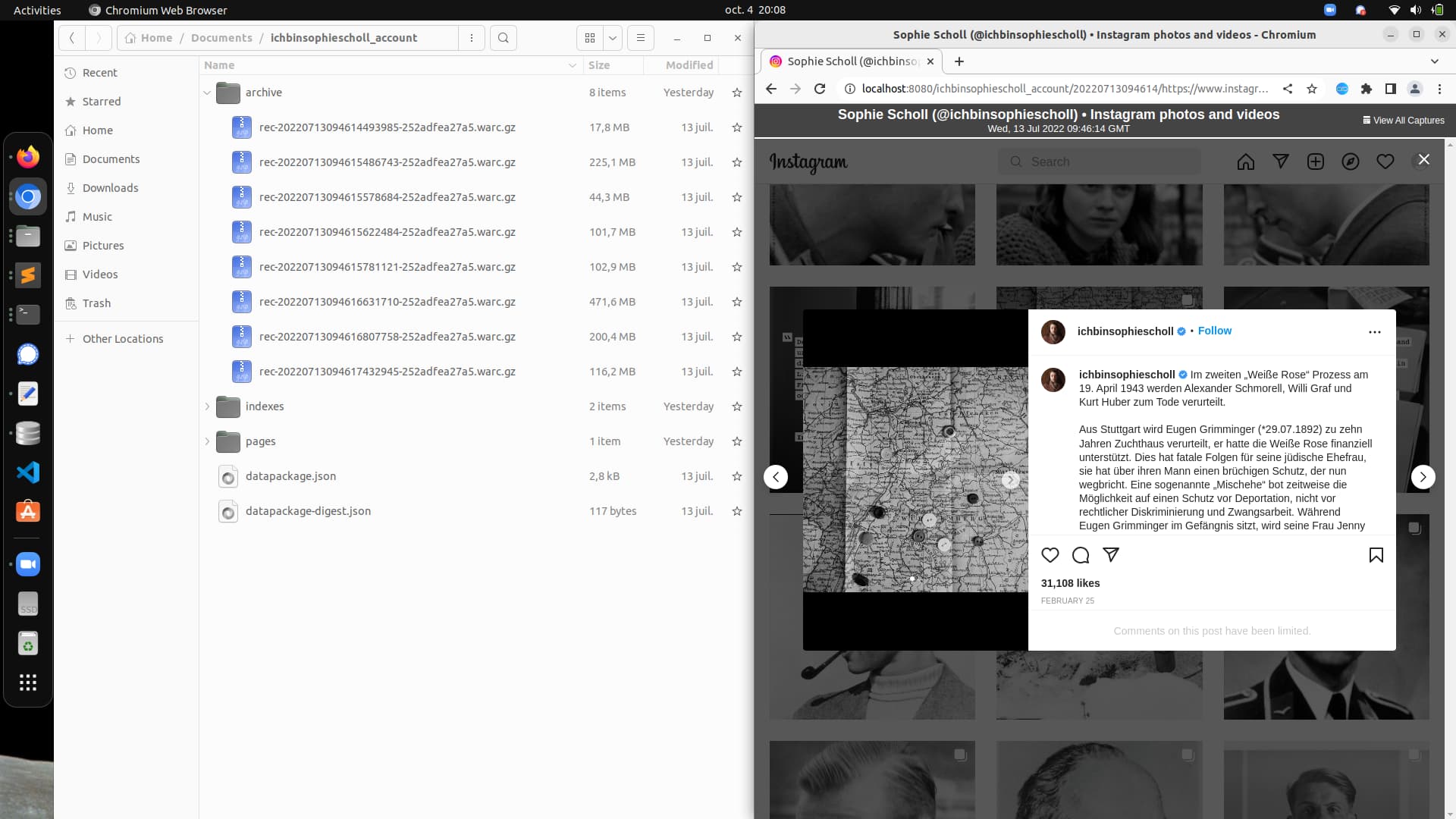
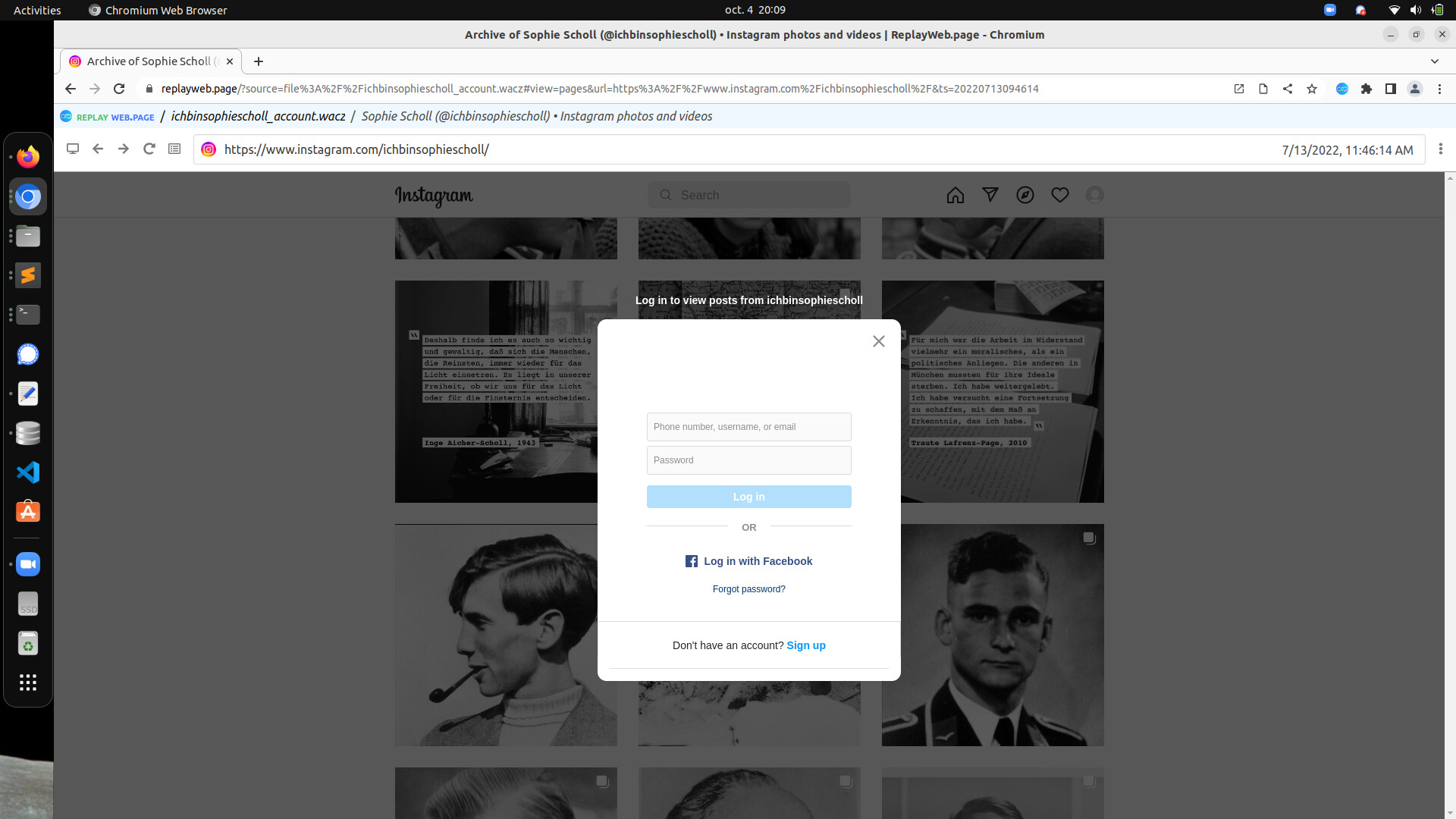
I’ve added the WACZ to replayweb.page. When I click on a post to open it, I get the Login pop-up instead of the post. But if I use pywb, everything works fine - all the data is there and I can view the posts - without getting the Login pop-up.
Is this a known issue? Is there something wrong with my files?
Thanks for raising this @mona I can confirm that I see this issue as well when using a logged in Instagram user profile with latest browsertrix-crawler and replayweb.page
Hi, would you be able to share the WACZ file in question? I haven’t been able to repro the issue where it is logged in pywb but not logged in replayweb.page?
Does the pywb collections have any other data in it, if so, perhaps could try in a new collection just in case data is loaded from a previous capture?
Actually I was mistaken, I guess my Instagram profile needed to be refreshed. I crawled the Instagram page with the latest browsertrix-crawler with the following configuration:
@Ed: The WACZ you’ve created works also in my environment. Thank you very much.
I captured the the page again with the configs you posted. And the replay with replaywebpage works fine too.
So, it seems like the error is in my WACZ file. I tried to reproduce the error with the command above but there is a problem in the process of crawling. When I reproduced it, I will post it.
This WACZ won’t work on replay web page app version 2.0.0 . I don’t know why, it does with ReplayWeb.page-1.8.14 and ReplayWeb.page-1.8.17. works too with archive web.page. you can convert it to zim format to be a future-proof or long-term preservation.
with this tool GitHub - openzim/warc2zim: Command line tool to convert a file in the WARC format to a file in the ZIM format . Installation was difficul to me on windows machine. I have a little knowldge with libzim ; may be you can do the conversion. am doing my warc stuff manually. all worked very well with all versions I have tested on . I even came to this post to know what is the ideal browsertrix options and what it’s results are. and to learn from the posted issues. so you can archive your account once again to see if it works with ver. 2.0.0 or to convert your file to zim.