We have just tested 1. time the newest release now with deduplication on our local devel platform - really a great work - a big step forward!
it realy make a difference and seems very stabil and without blocking bugs.
I have discovered some minor issues:
Anton tried to install a seperat redis dbs, but failed with that because of a allready used port. And it seems allready in place. We can deduplicate between crawls using the same deduplication collection. I think there was some misunderstanding of your docu.
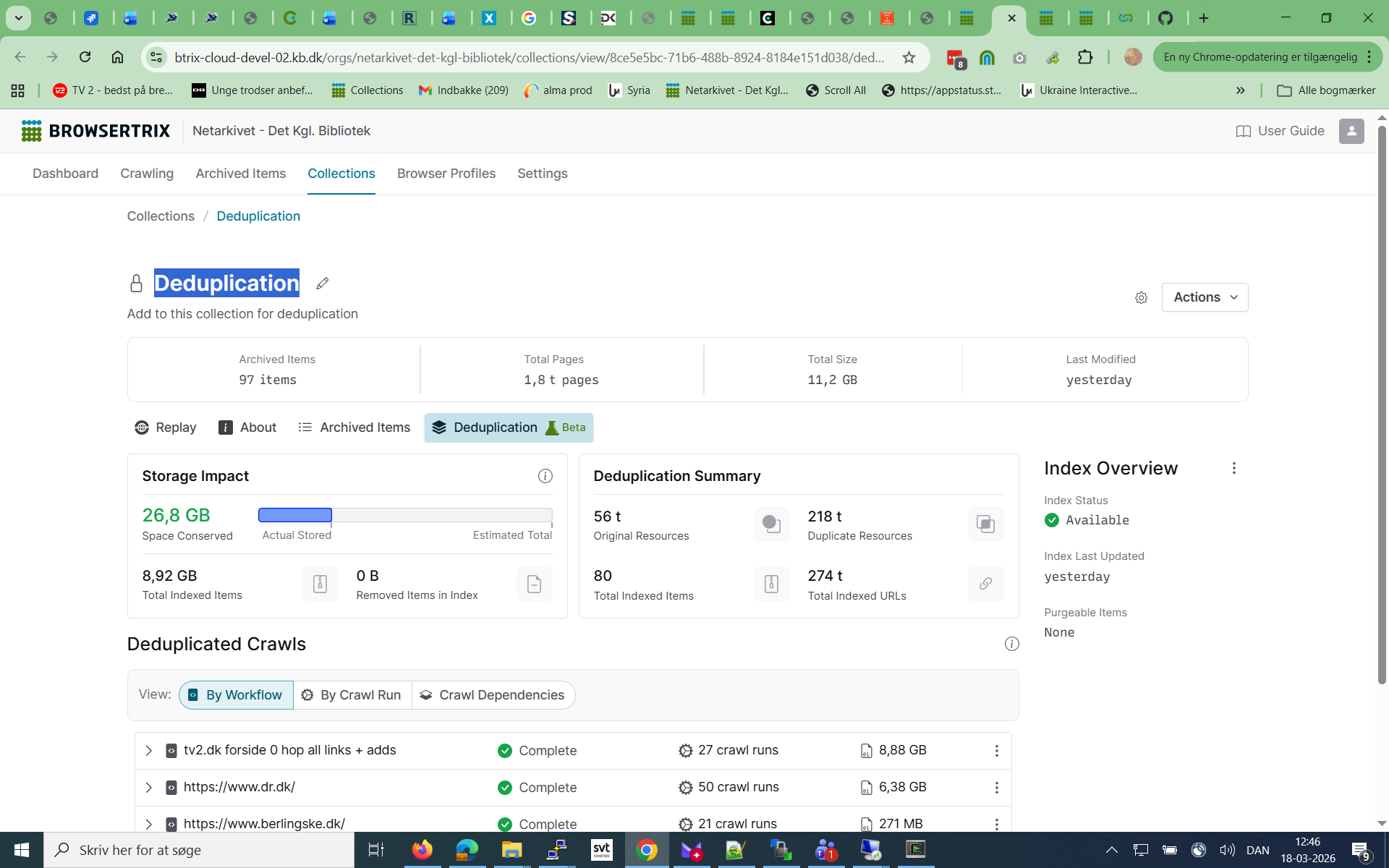
I mis a list of dudupped objects in the GUI per crawl - what is actually behind the word “Dependencies” - it takes too long time to dive into warc.gz files to try to find all revisits and go back to replay and verify it is replayed correctly…
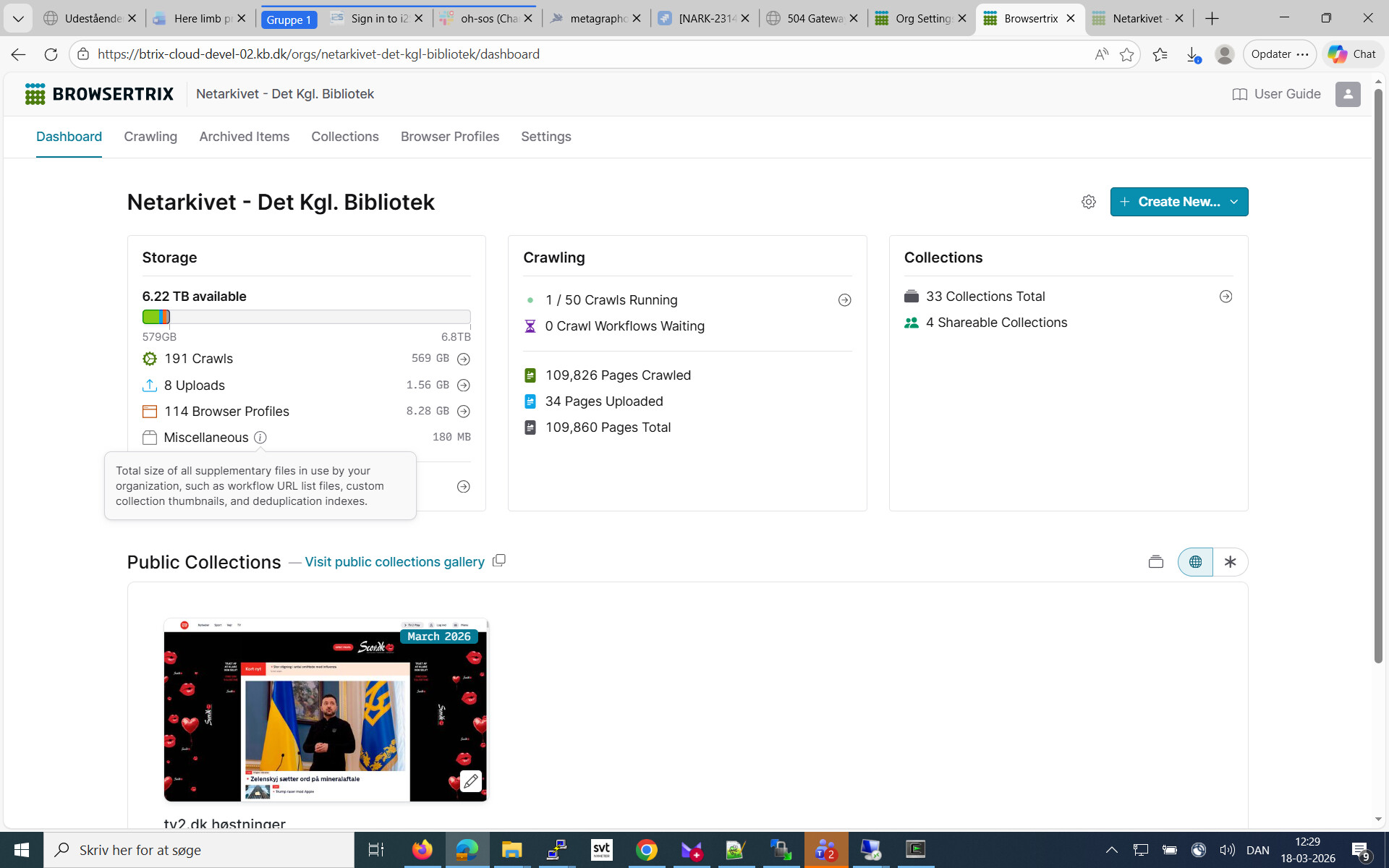
i’m wondering: the size in the dedup index in the Dashboard under Miscellaneous is only 180 MB compared to the Deduplication collection is 8,92 GB. It seems not mirroed in the Dashboard numbers.
Yes, you don’t need to install anything separate if you’re running Browsertrix in Kubernetes! Let us know which part is unclear in the documentation. (If you’re only using the crawler separately, then yes, you would need to manage it separately).
Dependencies just mean the crawls that contain the original records, to which the revisit records point to. This way, we know that if you delete a dependency, the replay will be broken, since the original will be missing. If you want to do replay in Browsertrix, you should not delete the dependencies, or you have to put everything in your wayback machine instance to get the full replay. We do have some stats per crawl that we haven’t added yet, if you mean total number of revisit records in the crawl? Or do you mean listing all the URLs (not pages) that were deduped?
This is the size of the index data itself when serialized to S3 (export from kvrocks), its really only relevant for the total storage used. The deduplication collection shows info about the collection, how much data crawled, how much was deduped, etc…
We will think about how to make this more clear.