Hi all, I’m attempting to use Browsertrix to download posts from a specific profile and have run into trouble with replaying the warcz file. It’s not clear if the issue is with the warcz, something I’m doing incorrectly with Browsertrix, or some kind of antibot tool Instagram has implemented. I mention that last bit because after making two attempts, I checked the URLs, and nothing was displayed in the browser, similar to what I saw on the replay page. After I logged into an IG account, I saw some message saying “reactivated,” and then the information seemed to be serving up fine in the browser.
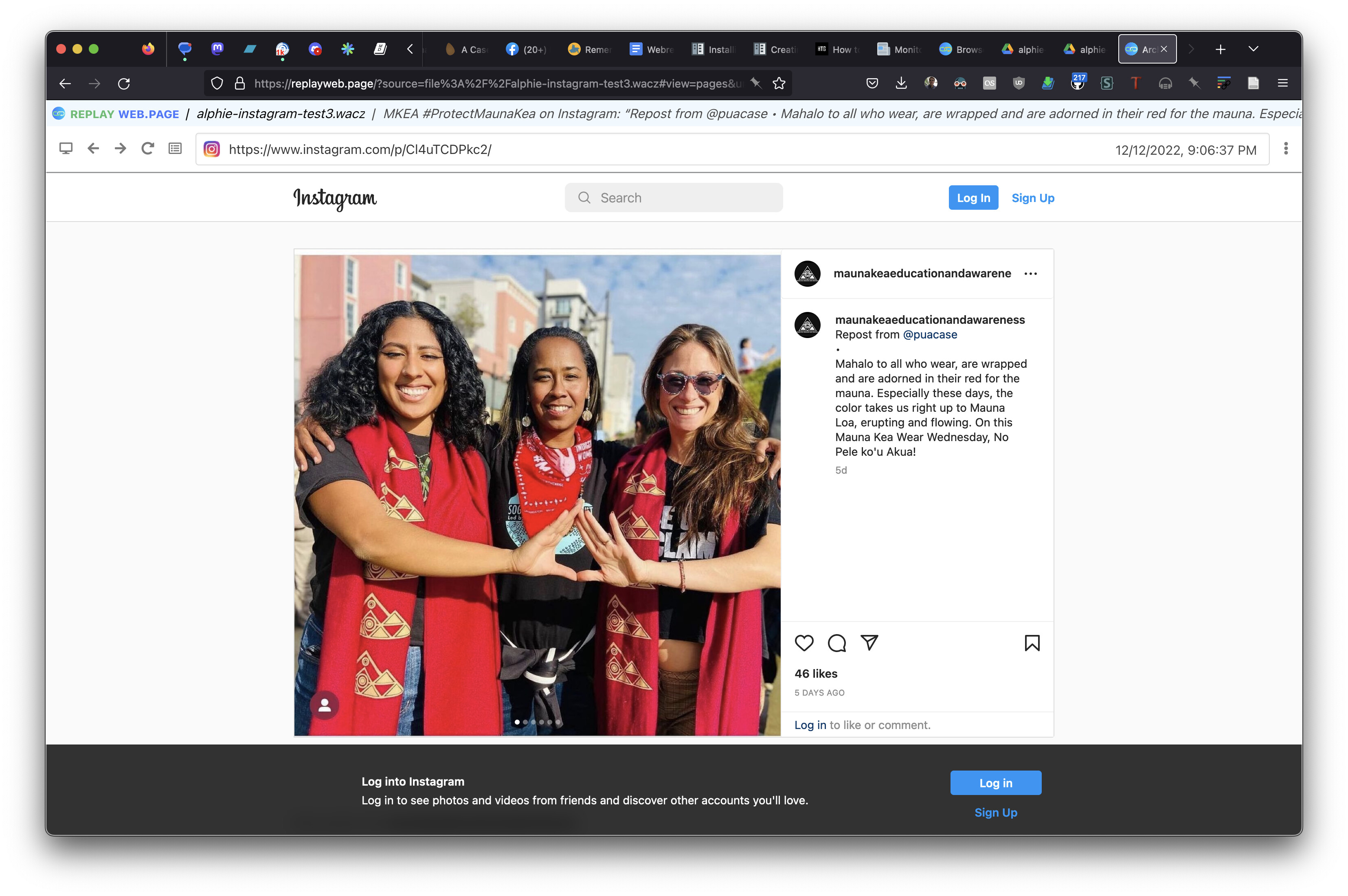
I downloaded alphie-instagram-test3.wacz from your Google Drive, and then loaded it locally in ReplayWebPage. After it opened up I navigated to this page: https://www.instagram.com/p/Cl4uTCDPkc2/ which seemed to be working?
Thanks for the reply. I do see the sheet for that post, but it starts to fail on the post dated 12/12/2022 4:06:38 PM which partially loads, and then posts 12/12/2022 4:06:38 PM to 12/12/2022 4:07:06 PM show no content at all except a brief image of the IG logo and then nothing.
I saw the same behavior when recording with browsertrix-crawler. I noticed that when I turned on the screencasting and watched the browser pages that they weren’t getting past the Instagram loading page. Which was weird because they appeared to be waiting long enough.
It looks like Instagram requires a login to view pages. I seem to remember having seen that before, but maybe the behavior has changed. You can verify by logging out and then trying to visit one of the pages.
Mahalo nui loa, @edsu! I’m still kicking the wheels of Browsertrix and am thrilled to learn about the profiles option. That is going to solve a lot of problems for this project. I did the test on my own and got back the archive with no replay issues
I was digging into the forum and saw a post@mona had done in October. I thought I’d take the approach of running the program on just the full account, but I’m running into replay issues there. I was watching the whole time in the screencast port, and it seemed to be pulling everything up. It looked like it captured the entire account, but upon replay, clicking on the individual posts loaded briefly but close quickly. Do you think this is an issue with my config file, docker browsertrix command, or the replay functionality?
I thought I’d take a crack again at my original approach to archive the individual posts for an account. It appears that the sitespecific behavior doesn’t autoplay posts with video or autoscroll (horizontally) for posts with multiple pictures when I do this. I do see it working when archiving an Instagram account page. Here’s the link to that attempt.
A second issue is I made the mistake of adding all 412 posts to the config file and ended up getting a 429 “too many requests” error. Is there a way to build in a delay between the tool archiving each page?
Hi @alphie sorry for the delay – the holidays intervened!
I ran your first crawl and saw the same results as you (no post details). I ran it again after removing scopeType: page which resulted in a larger file, but which seem to replay better? I think it defaults to scopeType: prefix when not specified.